Abstract
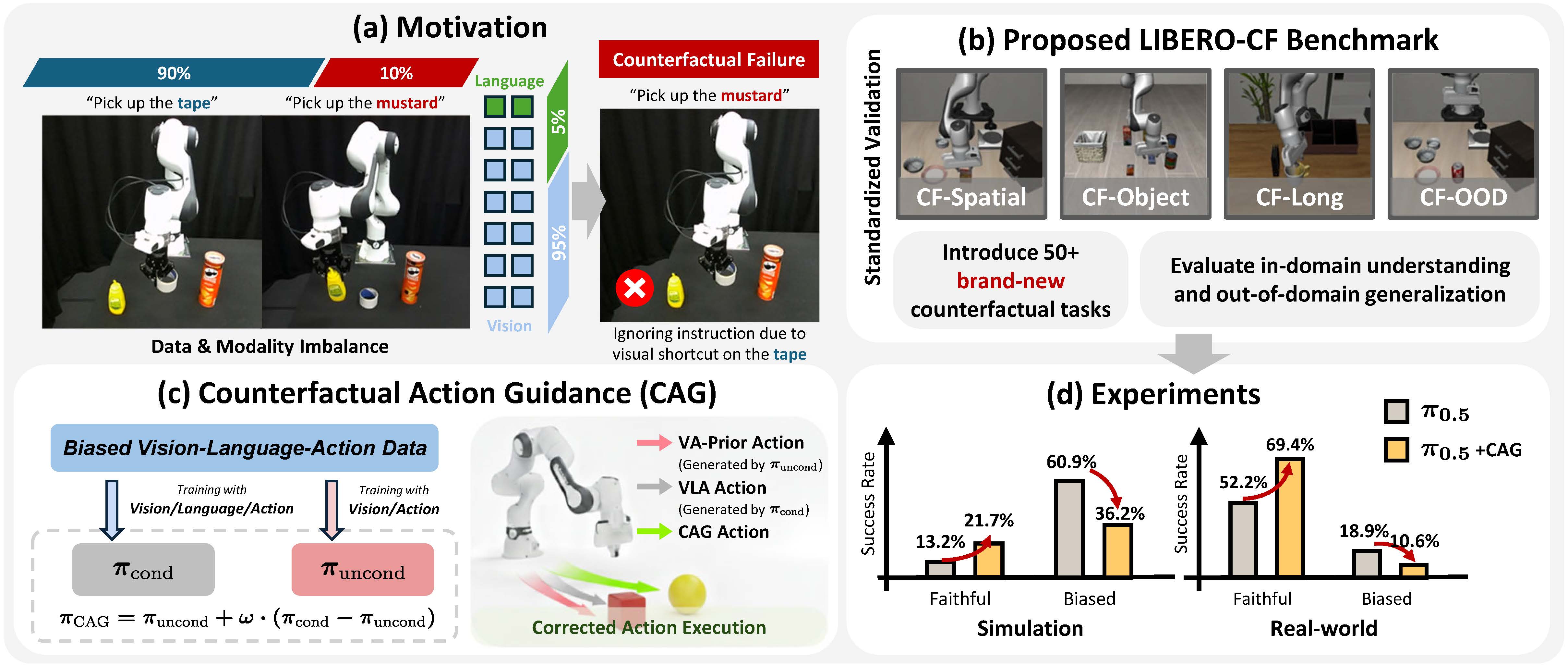
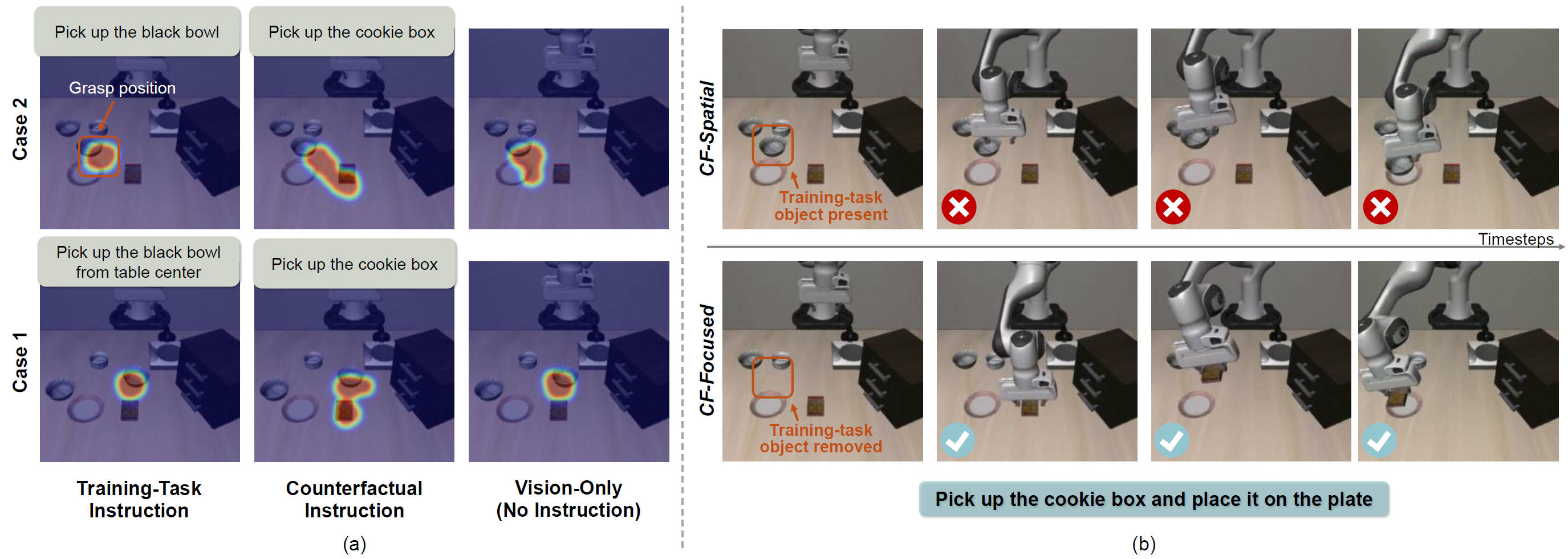
Vision-Language-Action models (VLAs) promise to ground language instructions in robot control, yet in practice often fail to faithfully follow language. When presented with instructions that lack strong scene-specific supervision, VLAs suffer from counterfactual failures: they act based on vision shortcuts induced by dataset biases, repeatedly executing well-learned behaviors and selecting objects frequently seen during training regardless of language intent.
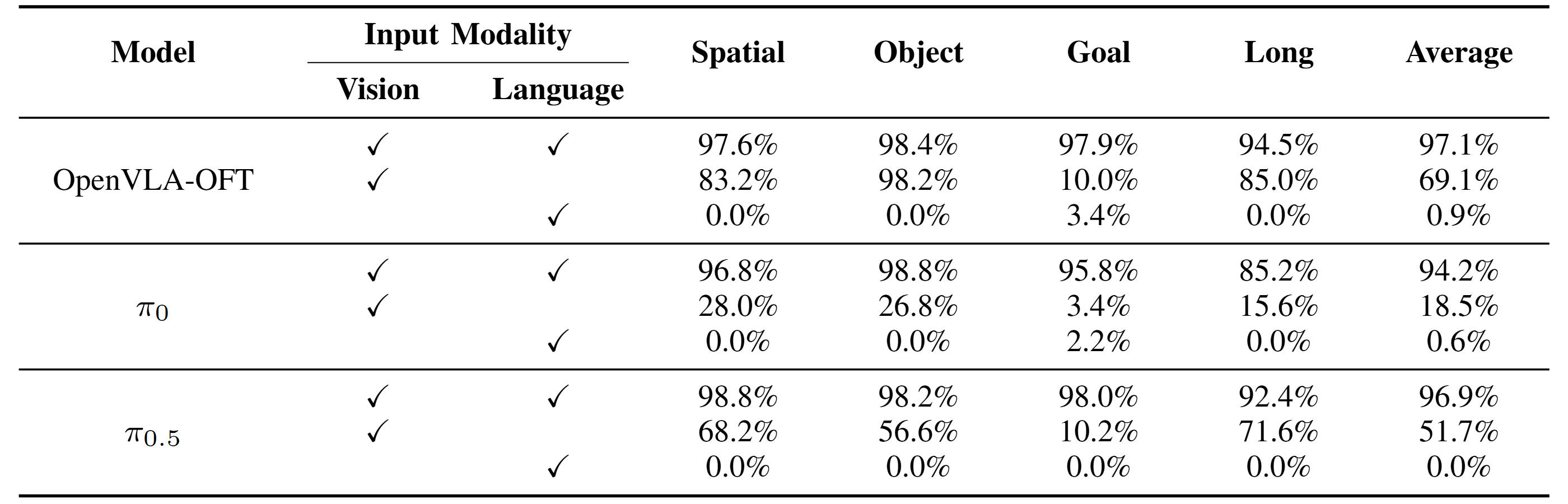
To systematically study it, we introduce LIBERO-CF, the first counterfactual benchmark for VLAs that evaluates language following capability by assigning alternative instructions under visually plausible LIBERO layouts. Our evaluation reveals that counterfactual failures are prevalent yet underexplored across state-of-the-art VLAs.
We propose Counterfactual Action Guidance (CAG), a simple yet effective dual-branch inference scheme that explicitly regularizes language conditioning in VLAs. CAG combines a standard VLA policy with a language-unconditioned Vision-Action (VA) module, enabling counterfactual comparison during action selection. This design reduces reliance on visual shortcuts, improves robustness on under-observed tasks, and requires neither additional demonstrations nor modifications to existing architectures or pretrained models.
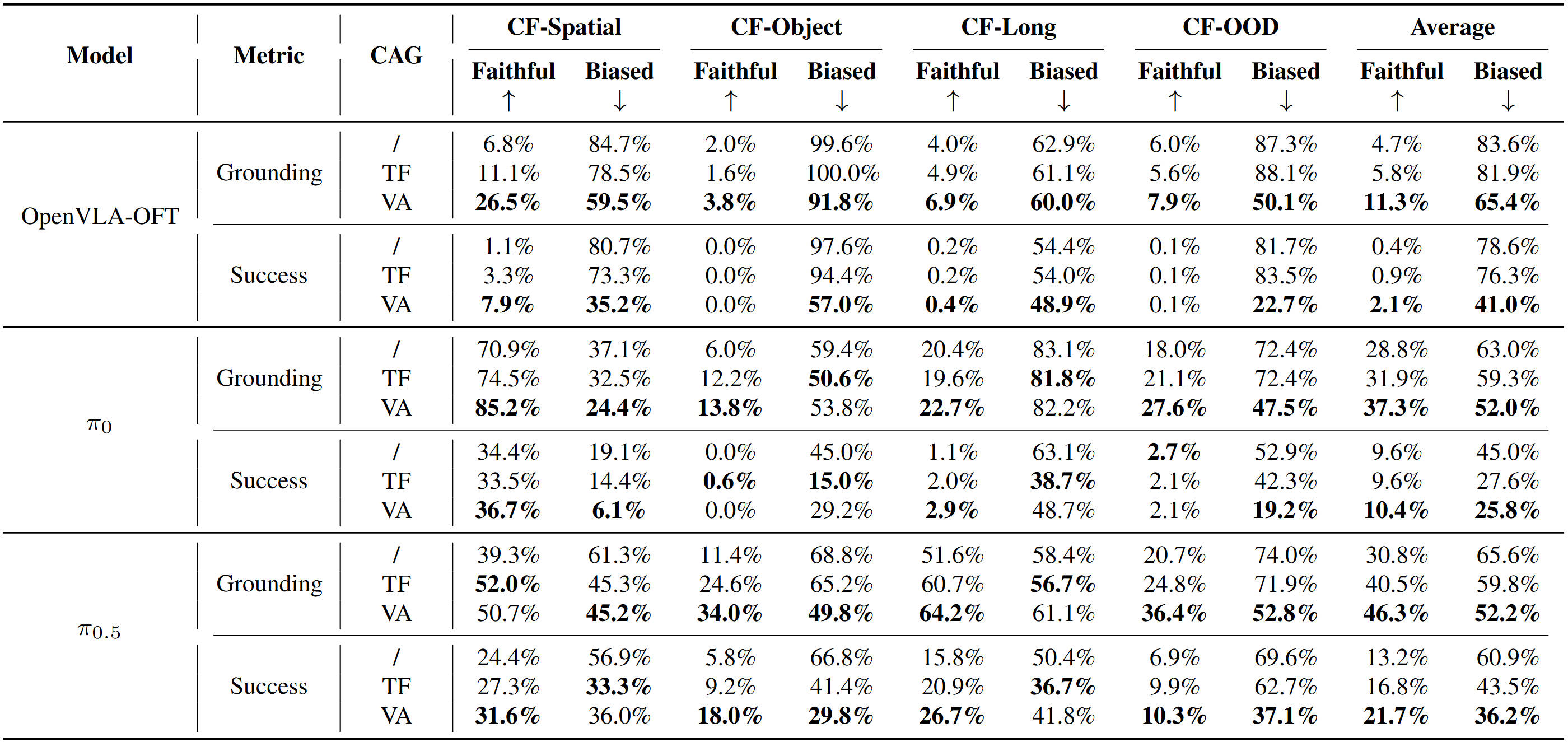
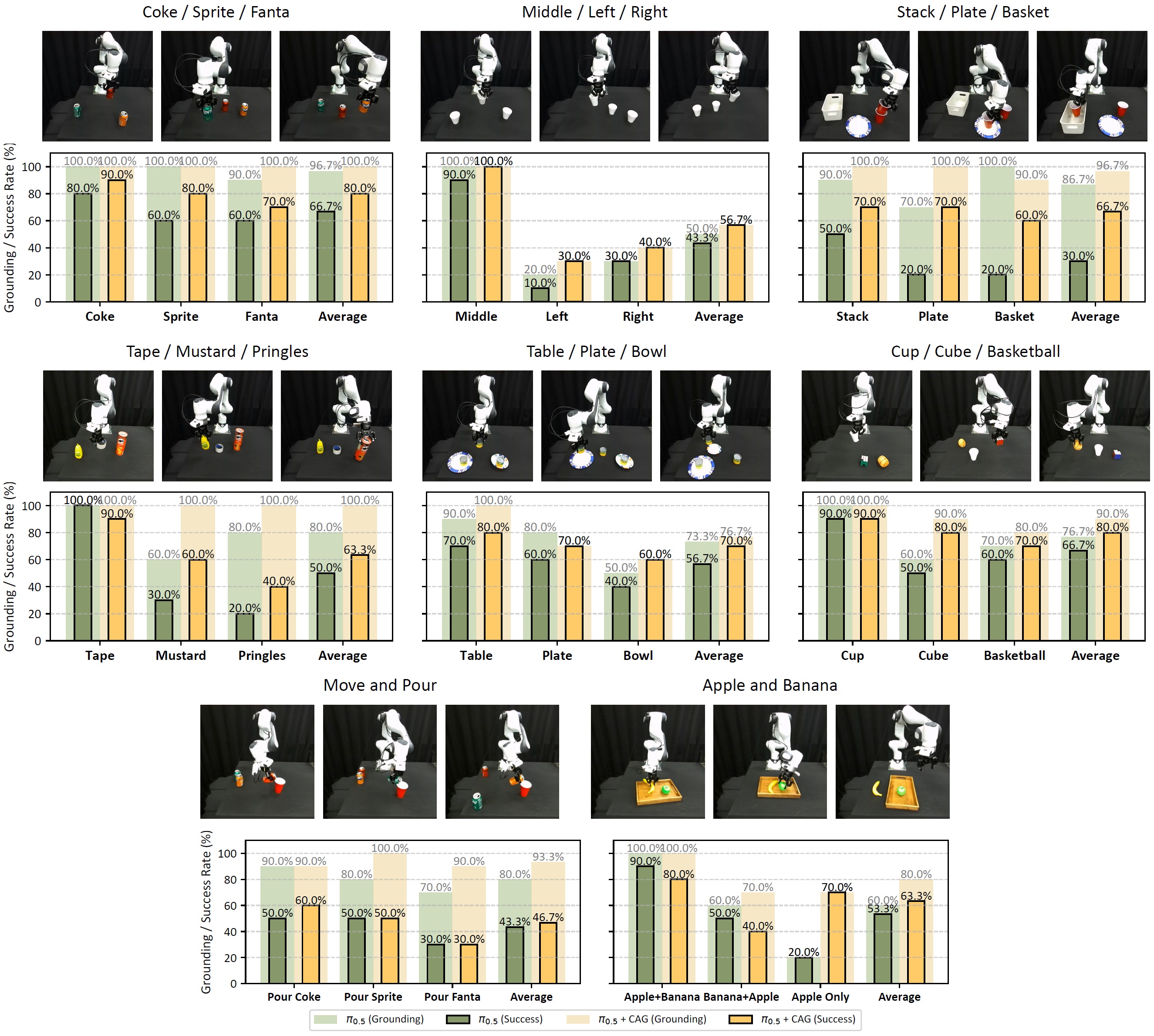
Extensive experiments demonstrate its plug-and-play integration across diverse VLAs and consistent improvements. For example, on LIBERO-CF, CAG improves π0.5 by 9.7% in language following accuracy and 3.6% in task success on under-observed tasks using a training-free strategy, with further gains of 15.5% and 8.5%, respectively, when paired with a VA model. In real-world evaluations, CAG reduces counterfactual failures of 9.4% and improves task success by 17.2% on average.